Server backed sessions (where the browser is given a random cookie value which is then associated with a larger chunk of serialized data on the server) are a very poor fit for relational databases. They are often created for every visitor, even those who stumble in from Google and then leave, never to return again. They then hang around for weeks taking up valuable database space. They are never queried by anything other than their primary key.
Database sessions also force an additional SQL statement to be executed for every page view to read that user's session, even if only to update a "Logged in as X" bar at the top of the page.
A fast key-value store like Redis is a much better fit for session data. The per-page overhead is far, far smaller than a round-trip to a regular database.
The implementation is simple - just a key/value pair per session. It's important to store the date the session was created so that sessions can be correctly expired. This can be done using a separate key, but a better solution is to use the EXPIRE command. Watch out though: writing to a key with an EXPIRE set on it (to update the session, for example) removes the expiry time entirely! You need to re-call EXPIRE after every write to the key. This is probably a good idea anyway, since it ensures user sessions expire N days after the last action by the user, not N days after they were first created.









![Commands on all keys
EXISTS [key]
DEL [key]
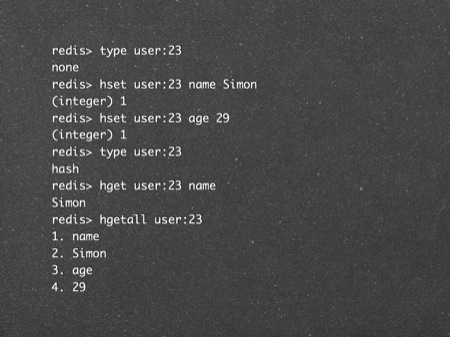
TYPE [key]
KEYS [pattern]
RANDOMKEY
RENAME [old new]
RENAMENX [old new]
EXPIRE [key ttl]
EXPIREAT [key ts]
TTL [key]](redis.011.jpg)
![Commands on strings
SET [key value]
GET [key]
MGET [k1 k2 k3...]
MSET [k1 v1 k2 v2..]
INCR / INCRBY
DECR / DECRBY
APPEND [key value]
SUBSTR [key 0 1]](redis.012.jpg)








![Atomic commands
GETSET [key value]
Sets new value, returns previous
SETNX [key value]
Fails if key is already set
MSETNX [k1 v2 k2 v2 k3 v3...]
Fails if ANY key already exists](redis.021.jpg)









![MONITOR
$ telnet localhost 6379
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
monitor
+OK
*1
$7](redis.031.jpg)







![Sets
SADD [key member]
SREM [key member]
SPOP [key]
SCARD [key]
SMEMBERS [key]
SRANDMEMBER [key]
SISMEMBER [key member]
SMOVE [src dst member]
SUNION / SUNIONSTORE
SDIFF / SDIFFSTORE
SINTER / SINTERSTORE](redis.039.jpg)










![List commands
RPUSH / LPUSH [key value]
LLEN [key]
LRANGE [key start end]
LTRIM [key start end]
LSET [key index value]
LREM [key count value]
LPOP / RPOP [key]](redis.051.jpg)
![[key start end]
Start and end are inclusive
LRANGE mylist 0 9 = first 10 items
They can be negative offsets from end
LRANGE mylist -2 -1 = last 2 items](redis.052.jpg)









![Blocking pop
Blocking pop from left or right
BLPOP [key1 key2... timeout]
BRPOP [key1 key2... timeout]
Returns immediately if a queue has items, otherwise blocks until timeout
Timeout = 0 means block forever](redis.063.jpg)



![zset commands
ZADD [key score member]
ZREM [key member]
ZCARD [key] ZSCORE [key member]
ZINCRBY [key increment member]
ZRANK [key member] - rank from bottom
ZREVRANK [key member] - rank from top](redis.067.jpg)
![zset commands
ZRANGE [key start end] - by index
ZREVRANGE [key start end] - by index
ZRANGE [key start end] WITHSCORES
ZREMRANGEBYRANK [key start end]](redis.068.jpg)
![zset commands
ZRANGEBYSCORE [key min max]
ZRANGEBYSCORE [key min max]
LIMIT [offset count] [WITHSCORES]
ZREMRANGEBYSCORE [key min max]
(between min and max inclusive)](redis.069.jpg)
![zset commands
ZUNION [dstkey N k1...kN]
ZINTER [dstkey N k1...kN]
Z***** [...] WEIGHTS [w1...wN]
Z***** [...] AGGREGATE SUM|MIN|MAX](redis.070.jpg)


















![Queue-activated shell scripts
while [ 1 ] do
redis-cli blpop restart-httpd 0
apache2ctl graceful
done
(Disclaimer: I haven’t dared try this)](redis.091.jpg)








